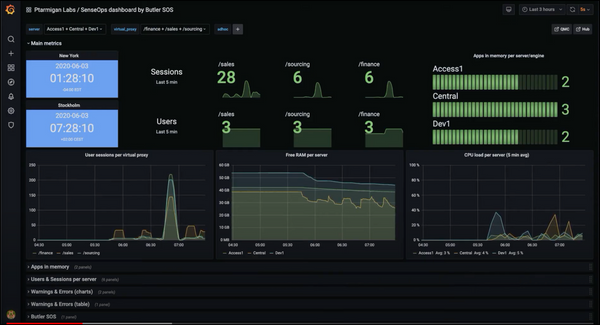
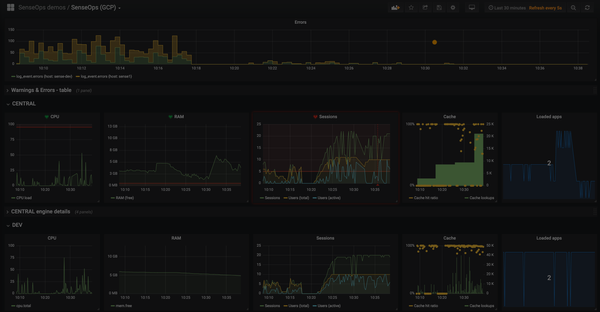
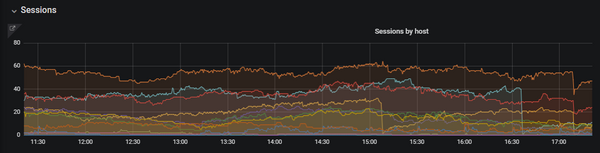
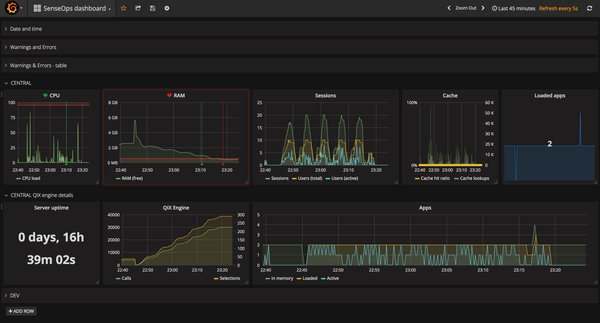
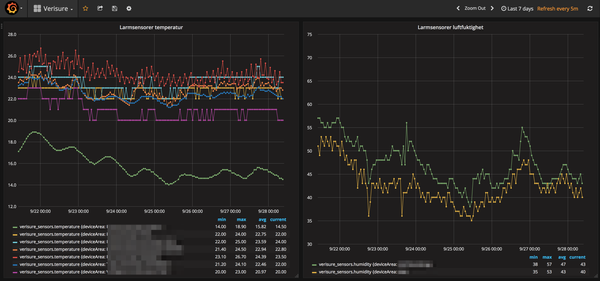
Before the summer the Butler tool turned two years old – time flies!
Over those years I have installed, tweaked and upgraded a fair number of Butler instances… Not a problem per se, but maintaining a production grade Butler instance does assume a certain level of experience around Node.js, Linux,